What I learned while creating Bookshelf (open source RAG Application)
I had the opportunity to speak at the AllThingsOpen.ai 2025 Conference recently. It was a wonderful experience to learn from and share with so many amazing fellow presenters and attendees. All Things Open AI 2025 session recordings are available now.
I spoke about several key aspects of Retrieval-Augmented Generation (RAG) and vector databases. The main topics I addressed included The Core Concepts of RAG, Embedding Models vs. Inference Models, Handling Multiple Embeddings and various Optimizations Beyond Naive RAG such as chunking strategies, enrichment with metadata, auto-merging retriever, and reranking models. Finally, I touched on Local Execution and GPU Utilization.
Bookshelf is a Generative AI application built as a rudimentary, but fairly capable, RAG implementation written in python. It can use an open source LLM model (running locally or in the cloud) or a GPT model via OpenAI’s API.
I used llama-index for orchestrating the loading of documents into the vector database. Only TokenTextSplitter is currently used. It does not optimize for PDF, html and other formats.
ChromaDb is the vector database to store the embedding vectors and metadata of the document nodes.
You can use any open source embeddings model from HuggingFace.
Bookshelf will automatically use the GPU when creating local embeddings, if the GPU is available on your machine.
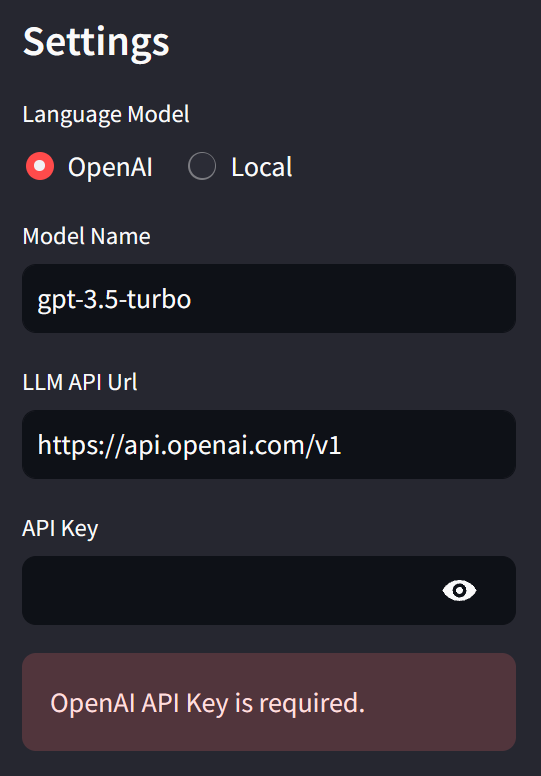
You can use OpenAI embeddings as well. There is no way to use a specific OpenAI embedding model or configure the parameters yet.
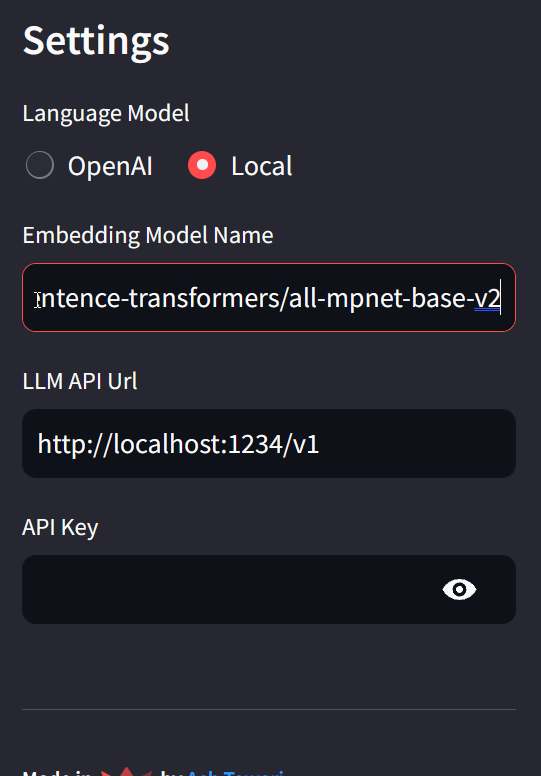
If you are running it locally, you will have the option of using an Open Source LLM instance via an API Url. In the screenshot, I am using an open source Embedding Model from HuggingFace (sentence-transformers/all-mpnet-base-v2) and The local LLM server at http://localhost:1234/v1
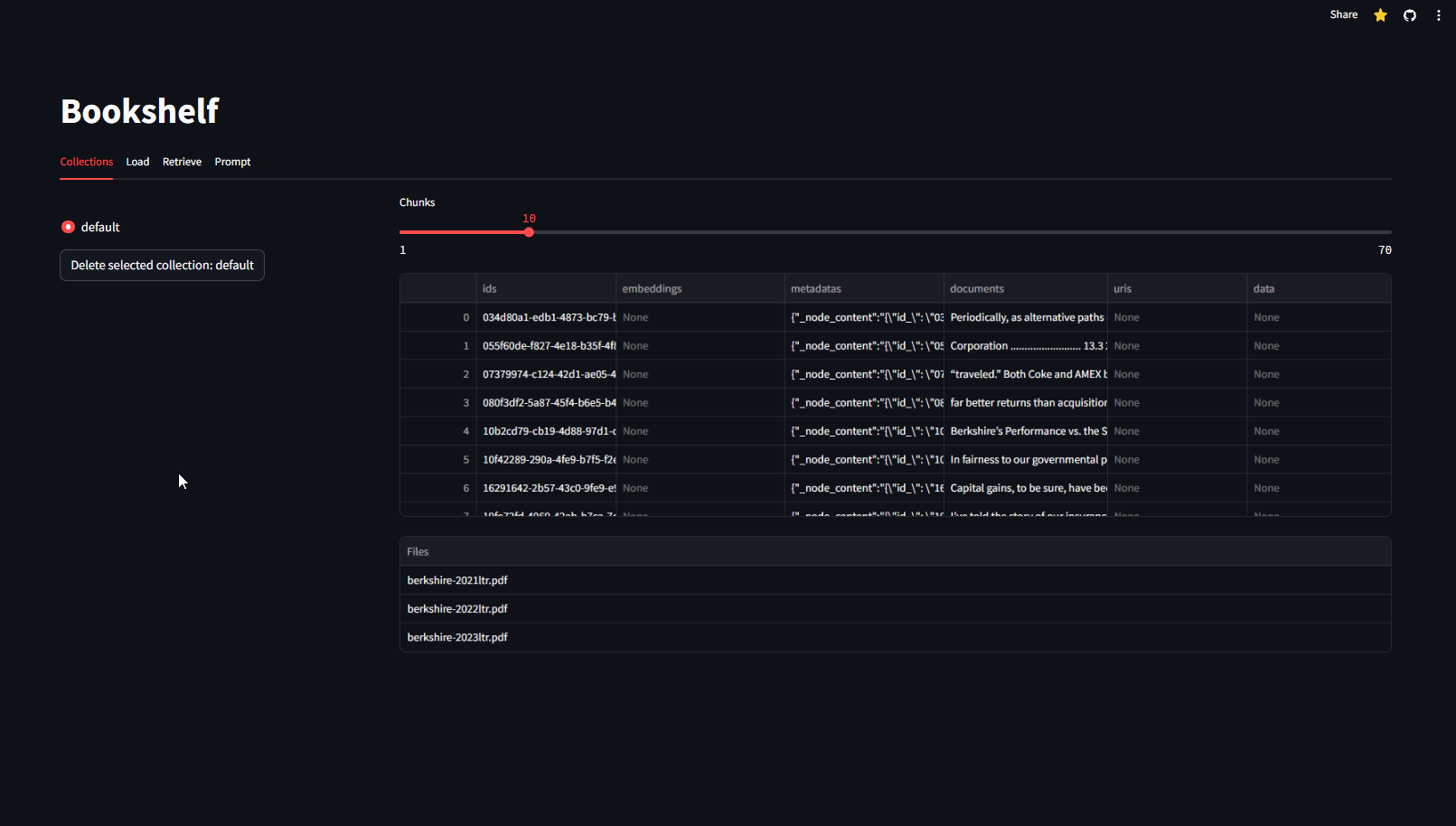
Collections tab shows all collections in the database. It also shows the names of all the files in the selected collection. You can inspect individual chunks for the metadata and text of each chunk. You can delete all contents of the collection (there is no warning).
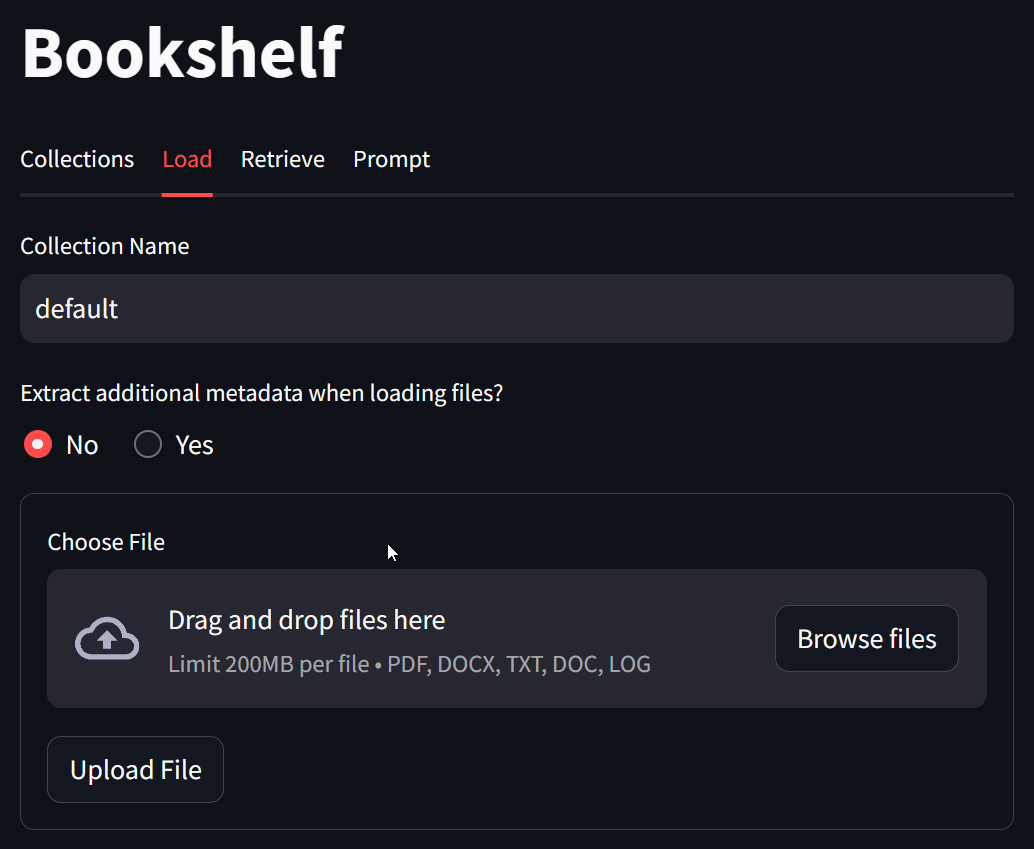
You can modify the collection name to create a new collection. Multiple files can be uploaded at the same time. You can specify if you want to extract metadata from the file contents. Enabling this option can add significant cost because it employs Extractors which use LLM to generate title, summaries, keywords and questions for each document.
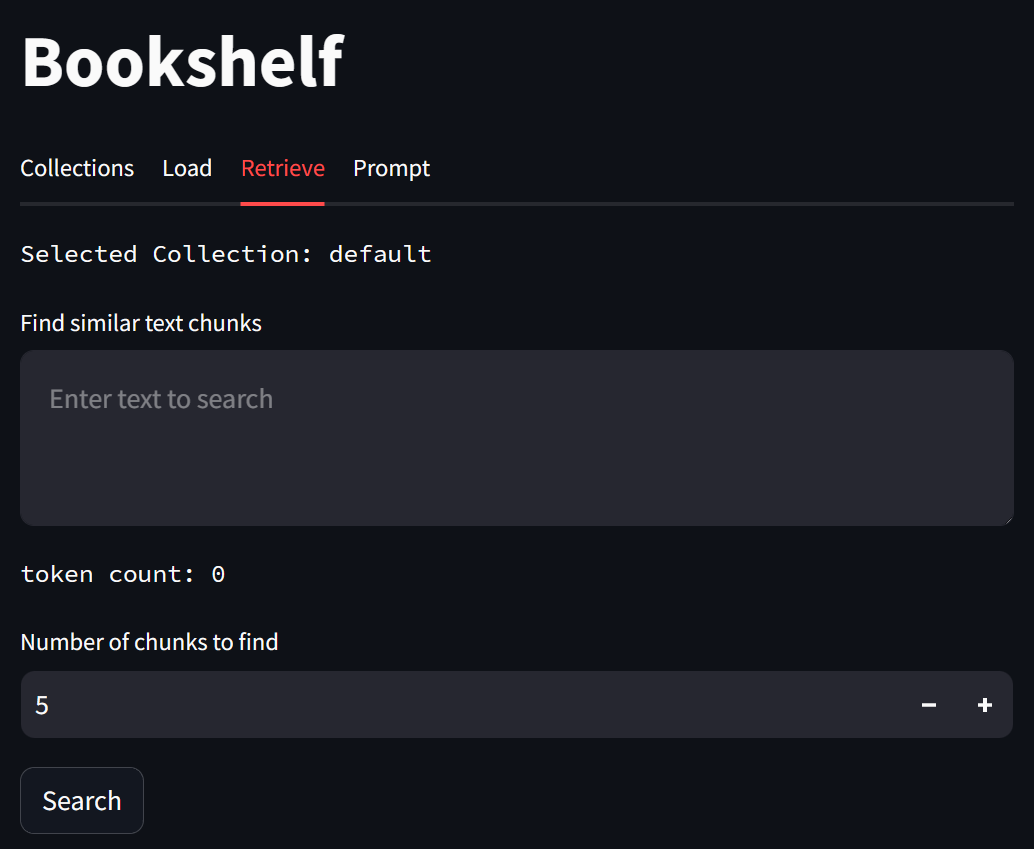
On the Retrieve tab, you can query chunks which are semantically related to your query.
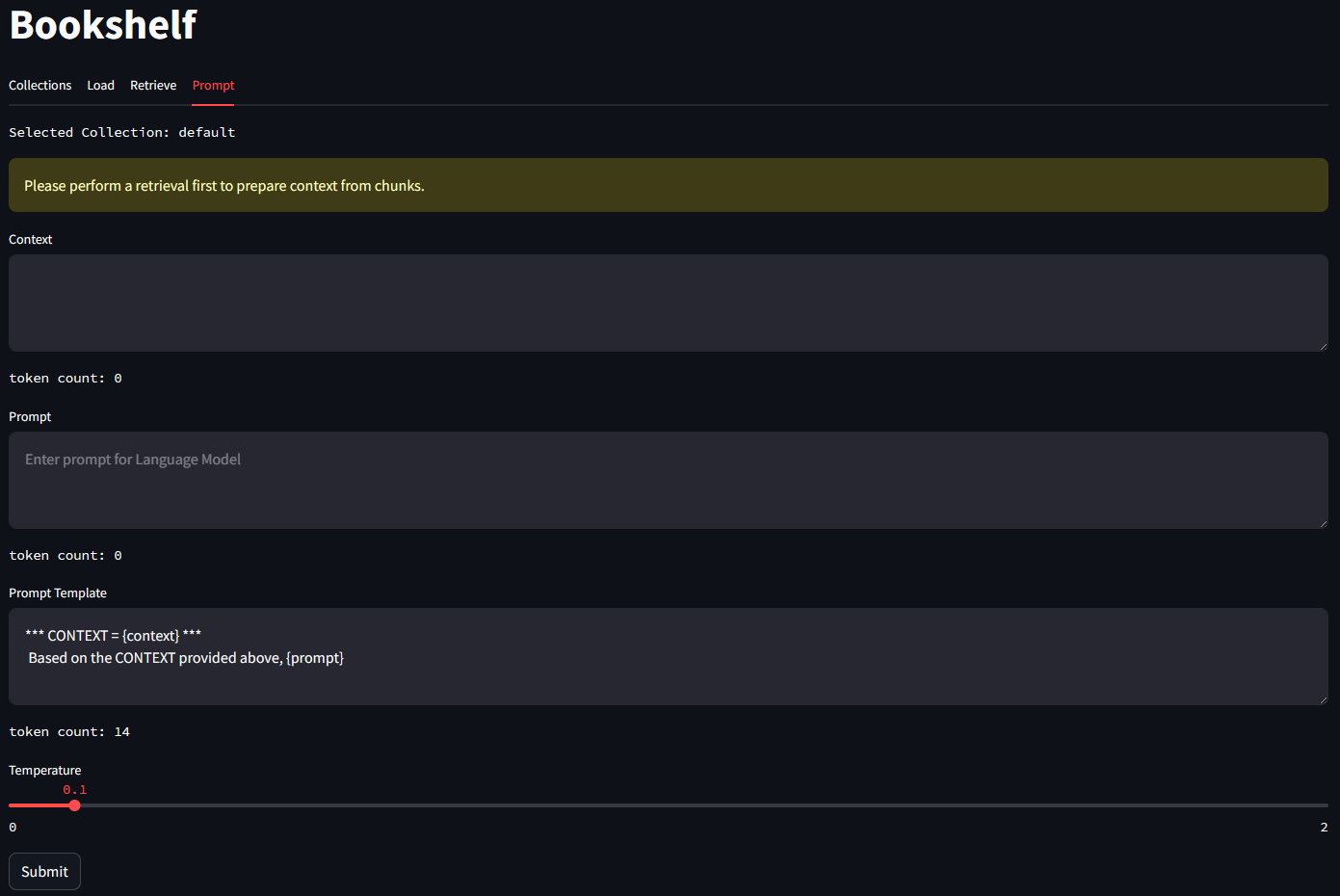
On the Prompt tab, you can prompt your LLM. The context as well as the Prompt Template is editable.
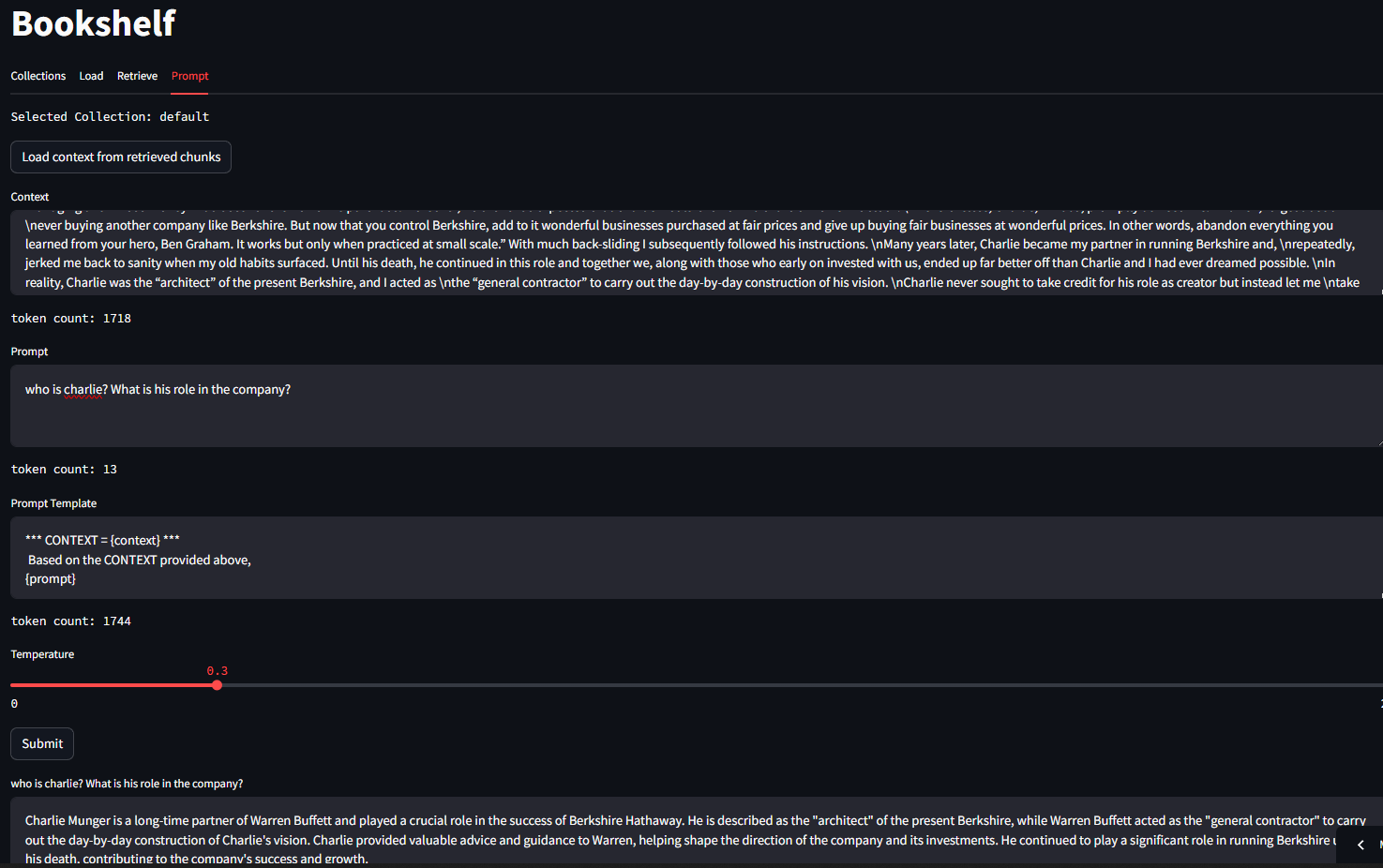
Here is an example of using the context retrieved from chunks in the Vector database to query the LLM.
This inference was performed using Phi3 model running locally on LMStudio.