What I learned while creating Bookshelf (open source RAG Application)
I had the opportunity to speak at the AllThingsOpen.ai 2025 Conference recently. It was a wonderful experience to learn from and share with so many amazing fellow presenters and attendees. All Things Open AI 2025 session recordings are available now.
I spoke about several key aspects of Retrieval-Augmented Generation (RAG) and vector databases. The main topics I addressed included The Core Concepts of RAG, Embedding Models vs. Inference Models, Handling Multiple Embeddings and various Optimizations Beyond Naive RAG such as chunking strategies, enrichment with metadata, auto-merging retriever, and reranking models. Finally, I touched on Local Execution and GPU Utilization.
I’m excited to announce the release of SPCHR. Pronounced as “speaker”. I know, I know. My apologies, it was too late at night and that’s the best I could come up with 😉
It is a Windows desktop application for speech-to-text transcription.
You can use it to “add” voice input to applications that don’t natively support it. It works anywhere you can type or paste text.
You can use it entirely locally on your PC if you like, so it is private and secure.
Key Features
Flexible: SPCHR can use either Azure Speech Services or a local OpenAI Whisper model, giving you the flexibility to choose between cloud-based and local transcription.
Zero Configuration: The application works immediately with local Whisper processing – no account setup required!
Global Hotkey: Start and stop recording from any application with Ctrl+Alt+L.
Seamless Integration: Transcribed text is automatically pasted into your active window.
Getting Started
Clone the repository
Build the solution using Visual Studio and run it
Press Ctrl+Alt+L and start speaking
Watch as your words appear in your active window
For those wanting cloud-based transcription, simply add your Azure Speech Services credentials to the configuration file.
Open Source
SPCHR is released under the MIT License, and I welcome contributions from the community. Whether you’re interested in adding features, fixing bugs, or improving documentation, your help is appreciated.
Do you remember which one of those boxes in the garage has your old phone? Or that toy your child wants to play with again? Or the tripod you need for your weekend trip? Oh what about that massager that you could really use right now! You would probably have to dig through those boxes to find it. Same problem when moving. There are always some boxes that you don’t want to open right away, but you wish you could open just the right one when you need something.
I have created WhichBox – your AI Assistant to find that box. It uses latest Vision AI models to help you find things quickly. Here’s what you do –
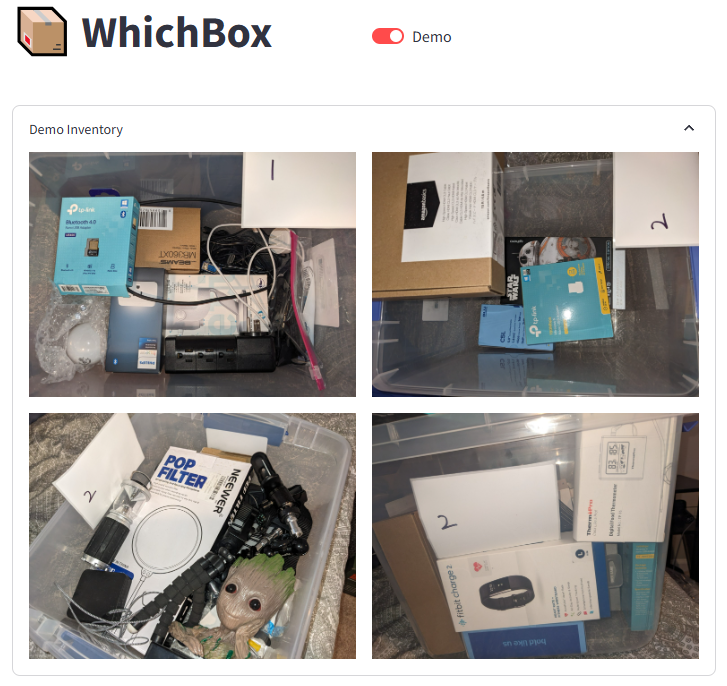
Take pictures of the content inside each labelled box to create an inventory.
Use WhichBox to easily identify the box containing the item you are looking for.
The demo has four photos of labelled boxes with some content in them. Note that there can be multiple photos of the same box. You can take photos as you are filling up the box to capture things at the bottom.
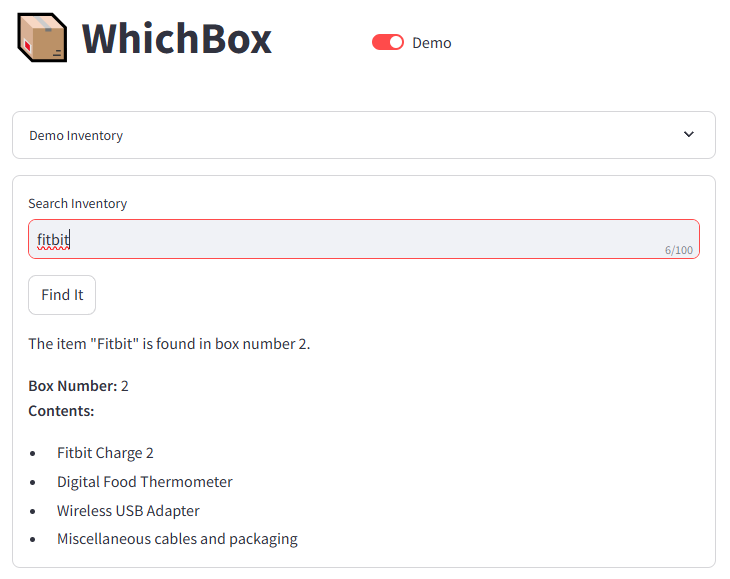
You can ask for a specific thing, like “Find Fitbit” or just “fitbit”
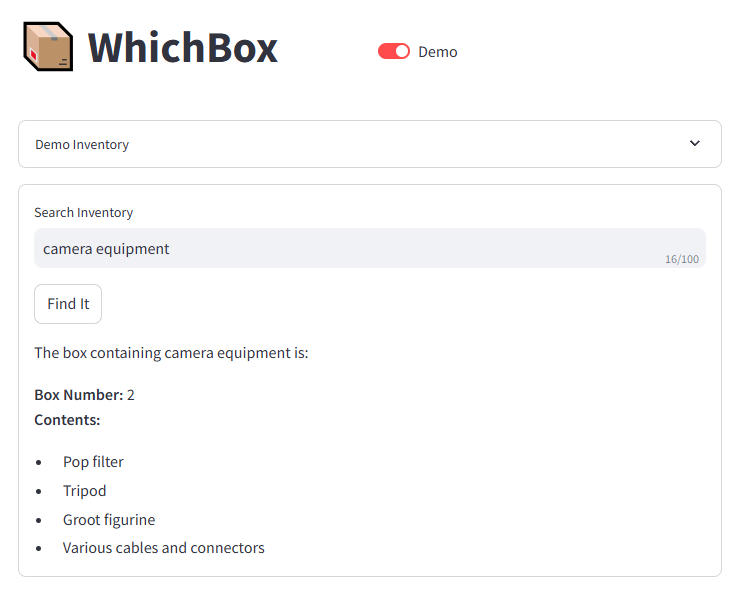
You can go for a general category, like “Camera Equipment”
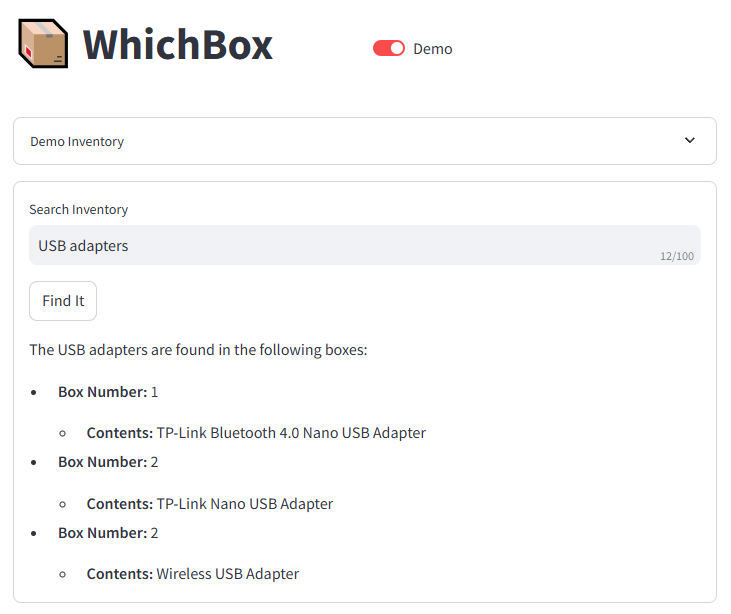
You can get all boxes containing “USB Adapters”
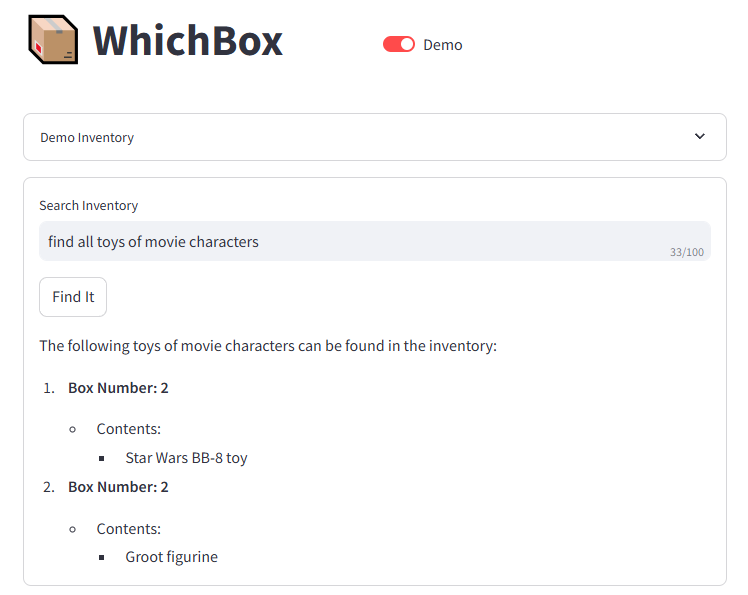
You can look for “Groot” or if you can’t remember the name of a specific toy then you can look for “all toys of movie characters”
For now, you can bring your own API Key and use your own photos to try this out.
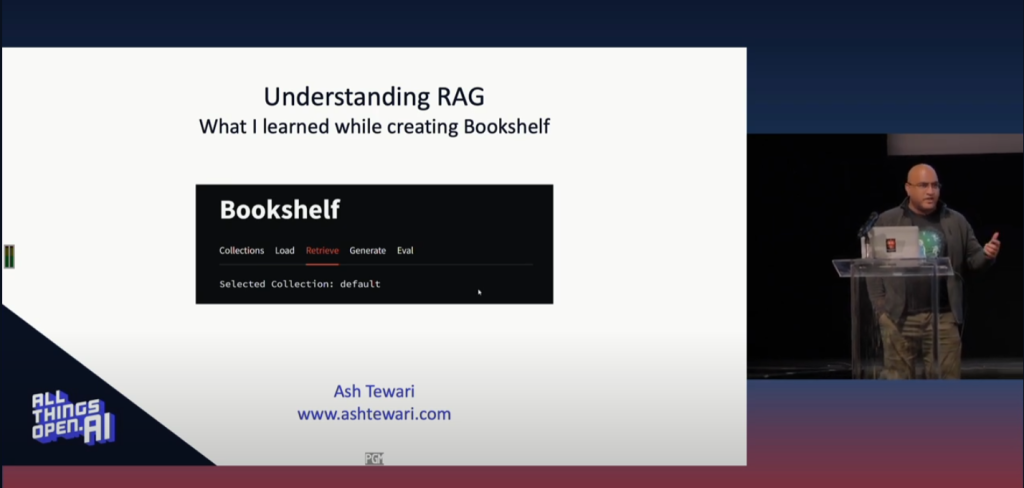
Bookshelf is a Generative AI application built as a rudimentary, but fairly capable, RAG implementation written in python. It can use an open source LLM model (running locally or in the cloud) or a GPT model via OpenAI’s API.
I used llama-index for orchestrating the loading of documents into the vector database. Only TokenTextSplitter is currently used. It does not optimize for PDF, html and other formats.
ChromaDb is the vector database to store the embedding vectors and metadata of the document nodes.
You can use any open source embeddings model from HuggingFace.
Bookshelf will automatically use the GPU when creating local embeddings, if the GPU is available on your machine.
You can use OpenAI embeddings as well. There is no way to use a specific OpenAI embedding model or configure the parameters yet.
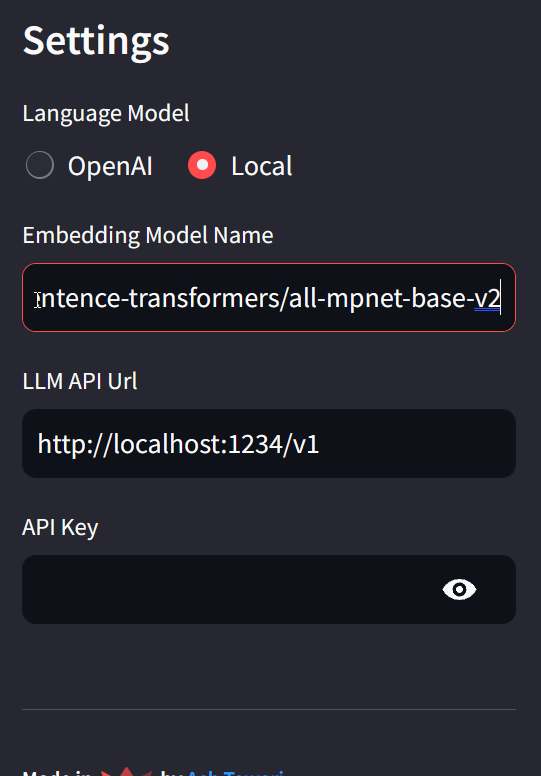
If you are running it locally, you will have the option of using an Open Source LLM instance via an API Url. In the screenshot, I am using an open source Embedding Model from HuggingFace (sentence-transformers/all-mpnet-base-v2) and The local LLM server at http://localhost:1234/v1
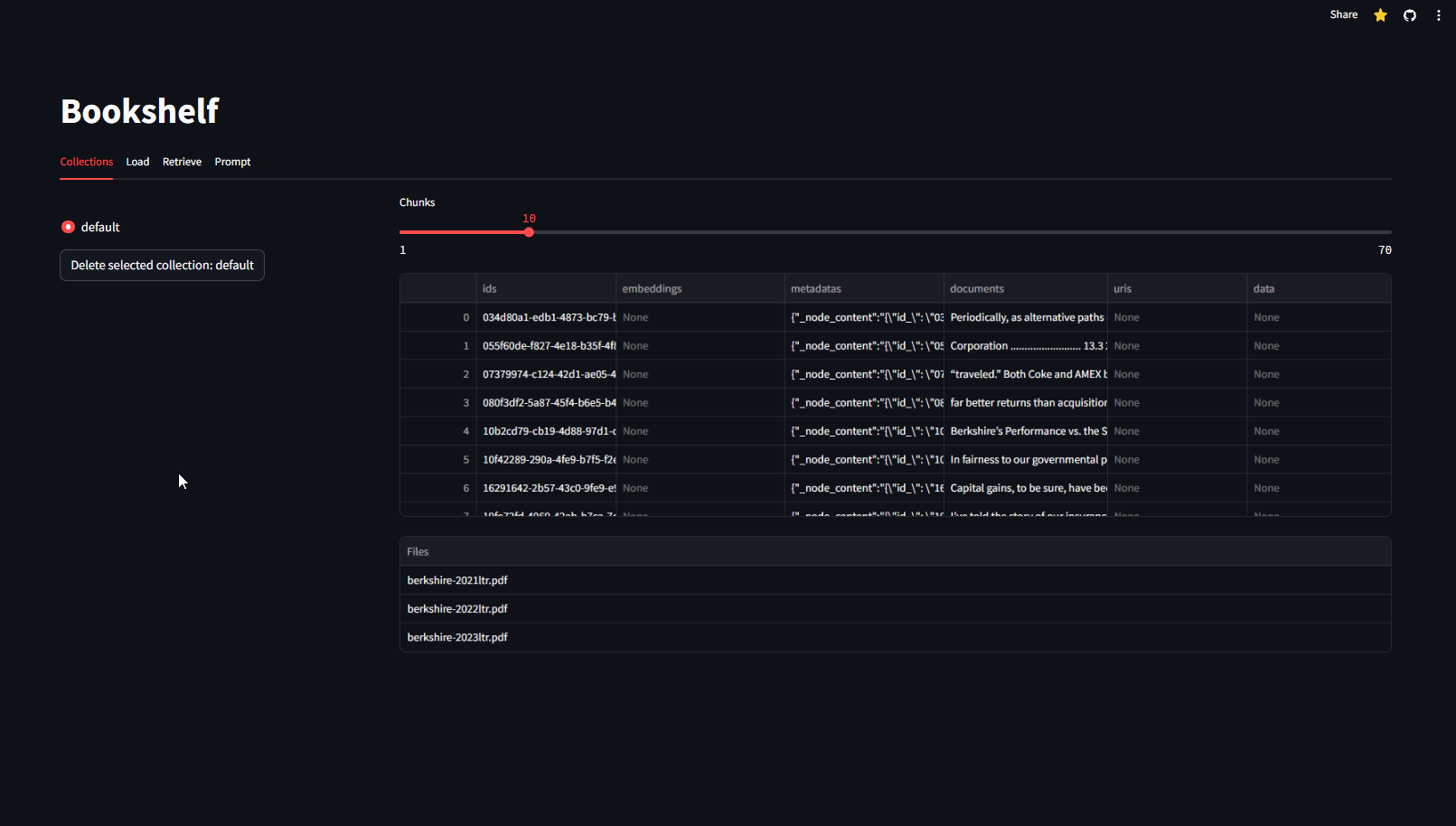
Collections tab shows all collections in the database. It also shows the names of all the files in the selected collection. You can inspect individual chunks for the metadata and text of each chunk. You can delete all contents of the collection (there is no warning).
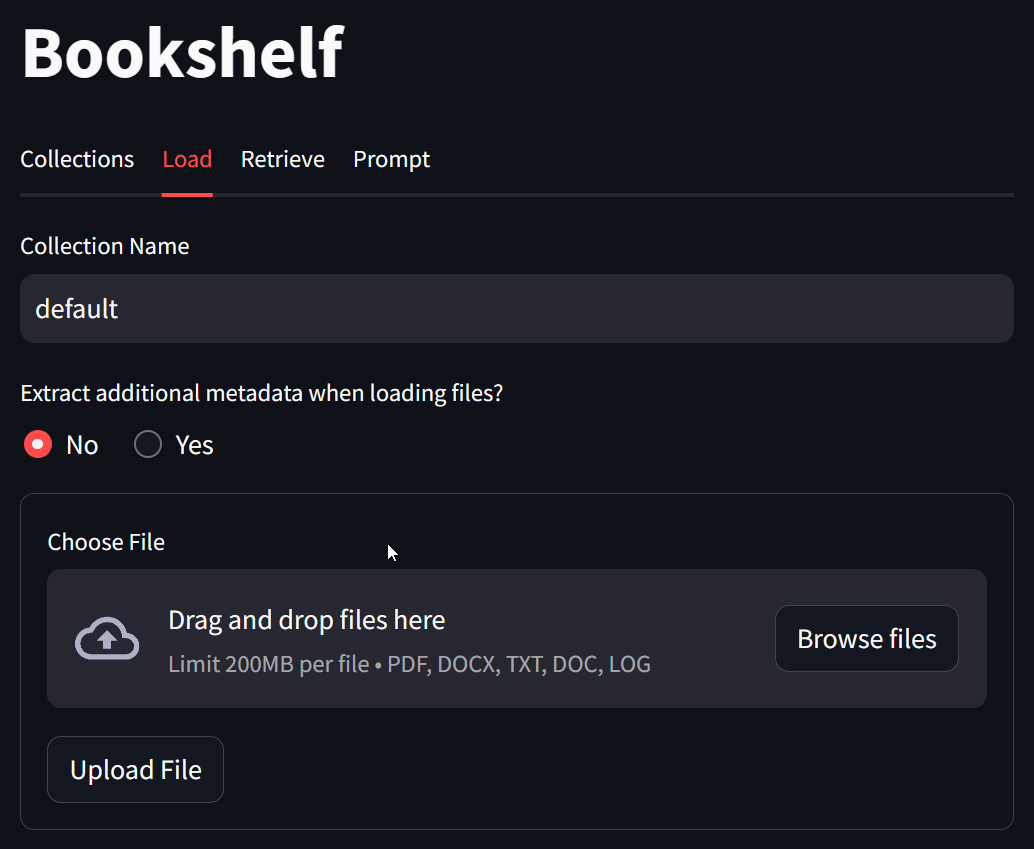
You can modify the collection name to create a new collection. Multiple files can be uploaded at the same time. You can specify if you want to extract metadata from the file contents. Enabling this option can add significant cost because it employs Extractors which use LLM to generate title, summaries, keywords and questions for each document.
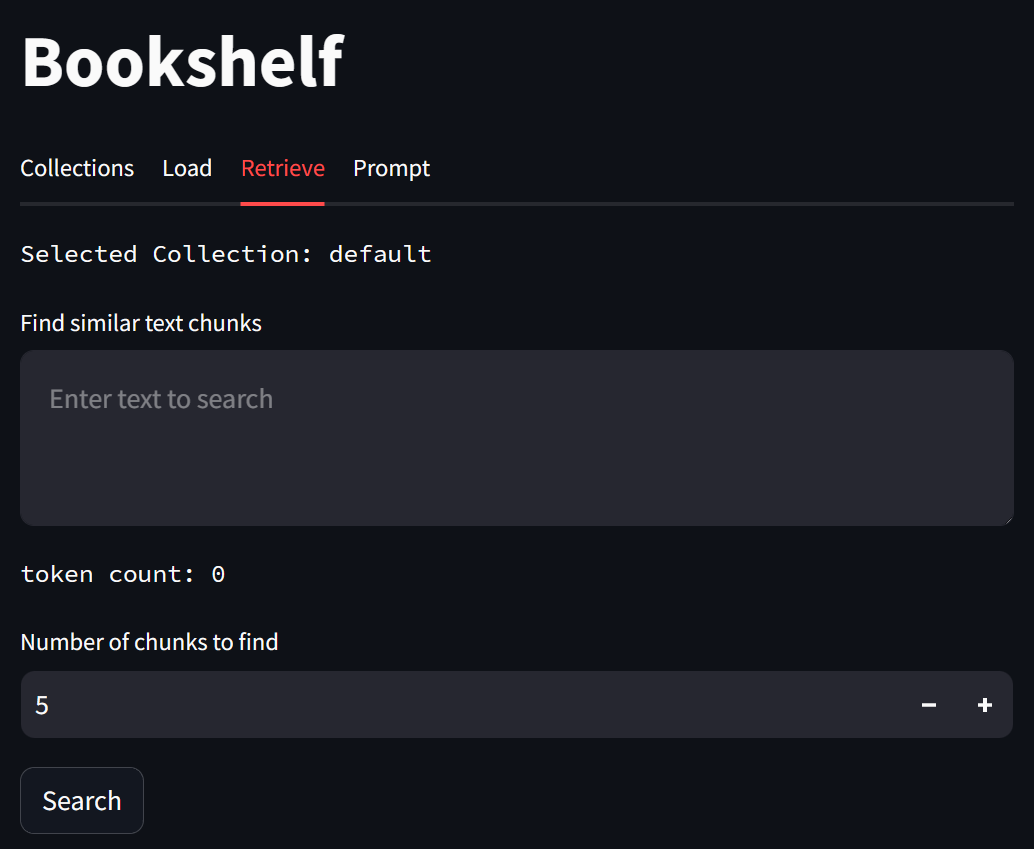
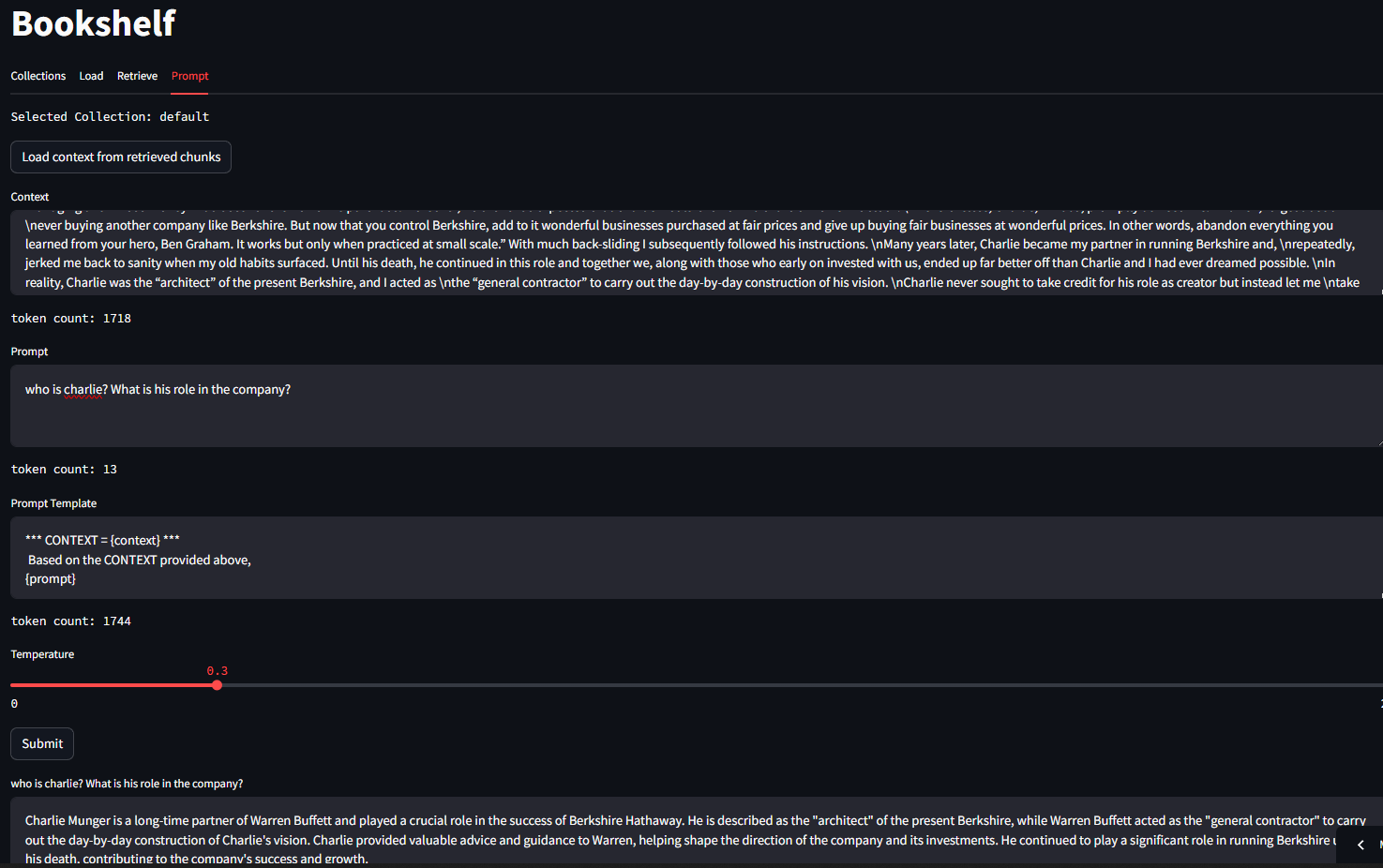
On the Retrieve tab, you can query chunks which are semantically related to your query.
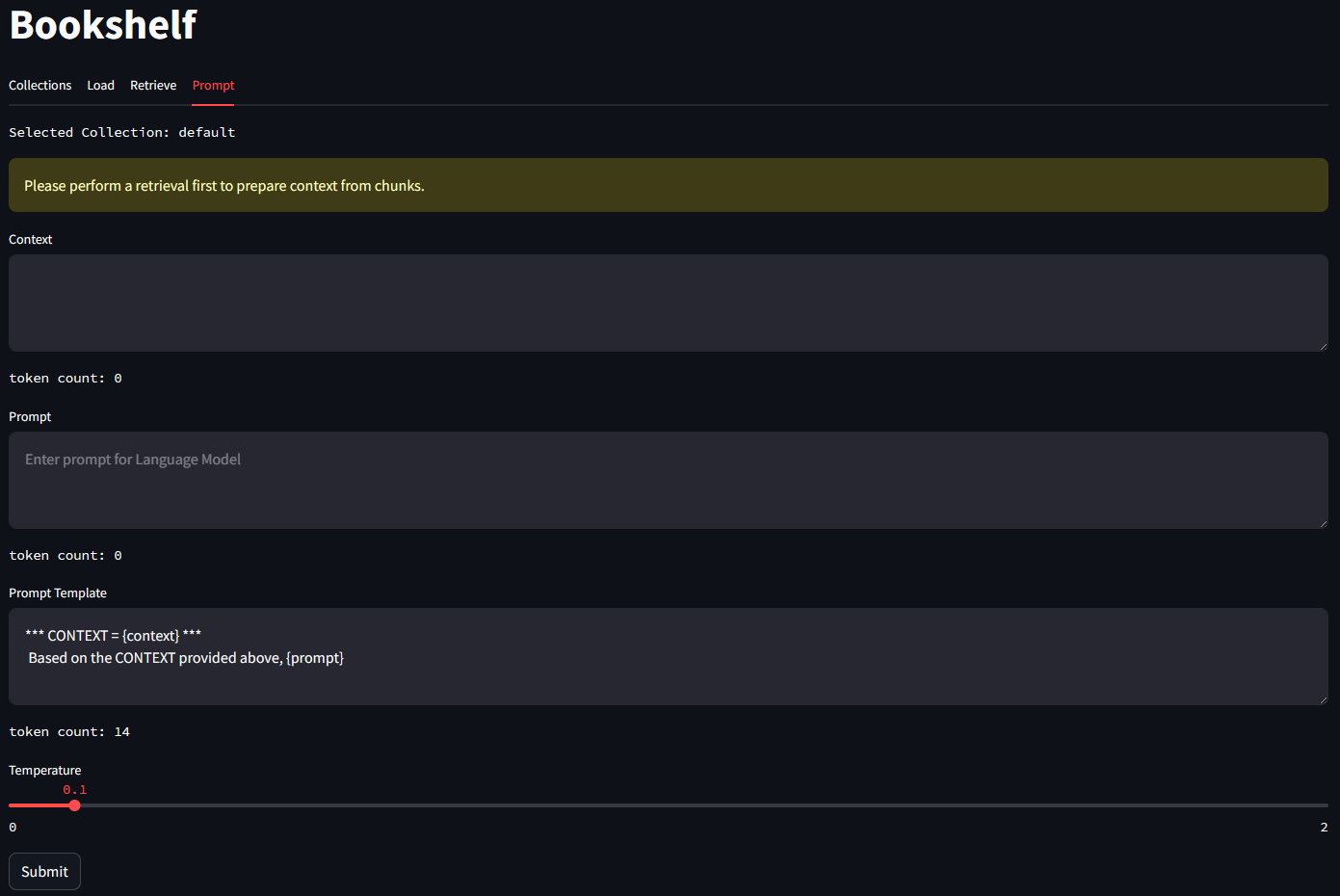
On the Prompt tab, you can prompt your LLM. The context as well as the Prompt Template is editable.
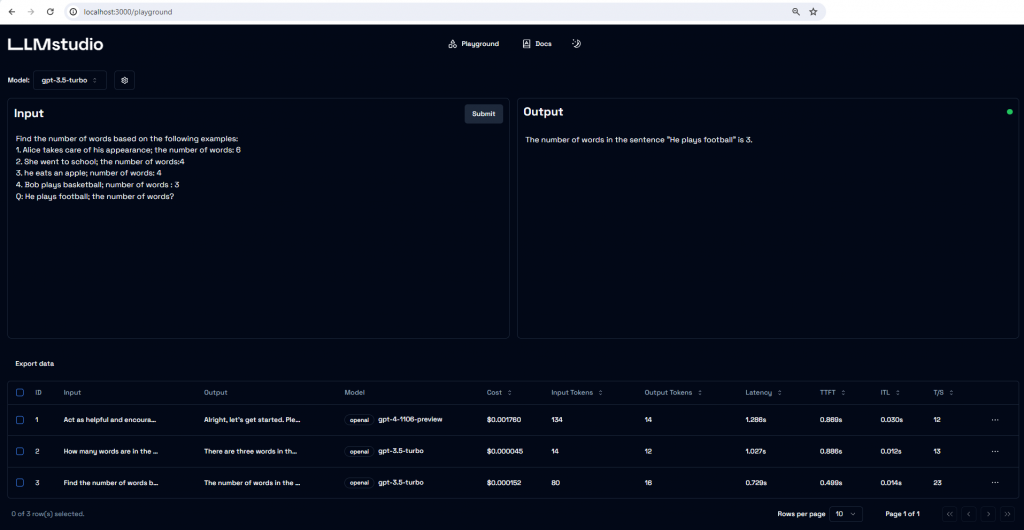
Here is an example of using the context retrieved from chunks in the Vector database to query the LLM.
This inference was performed using Phi3 model running locally on LMStudio.
Creating the ideal prompt can be the key to transforming a less than average outcome into one that is remarkably relevant. Discovering the right prompt often involves numerous revisions and a method of trial and error. I felt the need to refer to my past attempts, modifications made to prompts, LLM models I tried and other LLM settings as well relative cost of these combinations. There are a few options to help with this : promptflow, langsmith, LLMStudio and others.
I tried LLMStudio and promptflow. This article is about LLMStudio.
If you are installing LLMStudio on Windows, use WSL. Here are the steps :
Install Node v18, if you run into ReferenceError: Request is not defined at Object.<anonymous> (/home/ash/miniconda3/lib/python3.11/site-packages/llmstudio/ui/node_modules/next/dist/server/web/spec-extension/request.js:28:27)
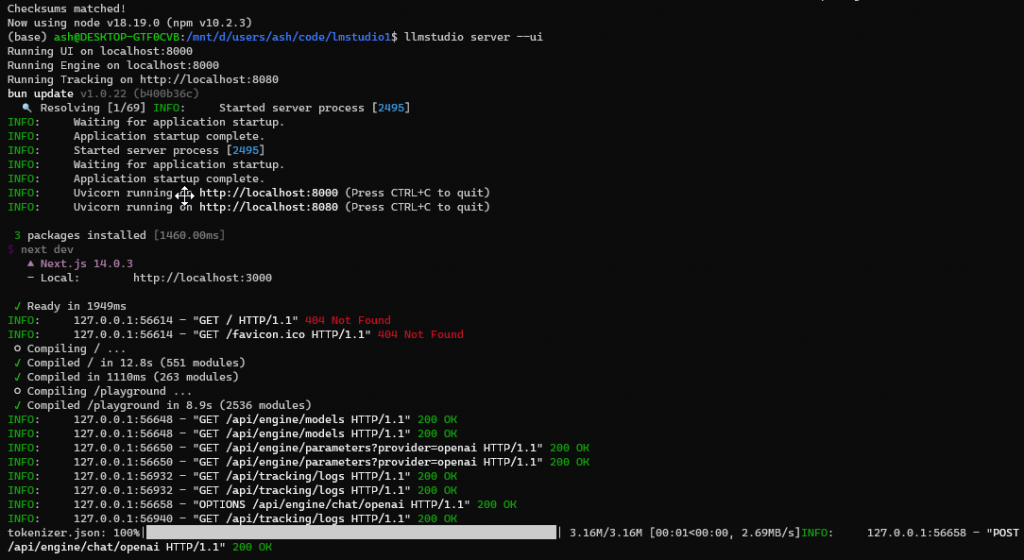
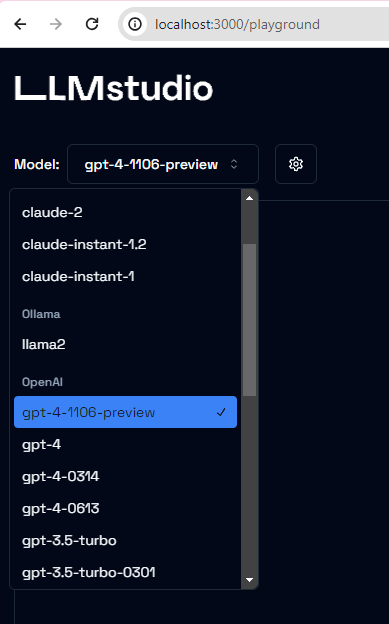
(base) ash@DESKTOP:/mnt/d/code/lmstudio$ llmstudio server –uiLLMStudio is available at http://localhost:3000You can select the LLM model you want to work with from the drop-downSpecify LLM parameter settings
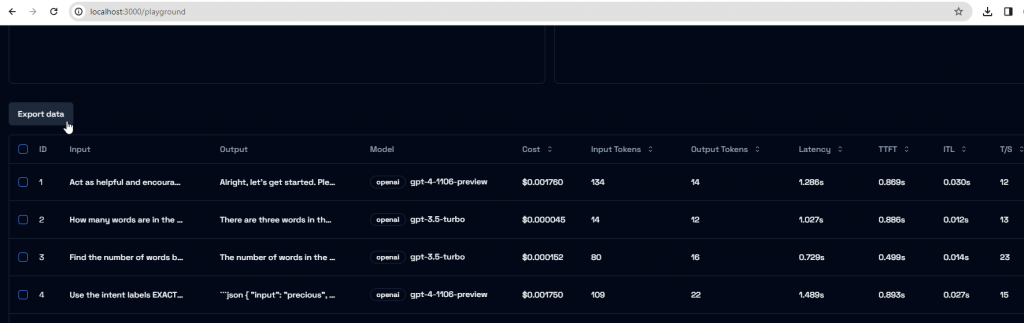
Export the execution data as csv file by clicking on [Export data] button. This data includes the input, output, LLM model, Input and Output tokens as well as cost.
I have been delving into Advanced Prompt Engineering and Security techniques for Large Language Models (LLMs). As an exercise, I have created a custom GPT in ChatGPT to help practice spelling of English words. Spell It GPT is secured with Advanced Prompt Engineering techniques to guard against common attack vectors, including Direct Prompt Injection, Prompt Leaking, Role Playing, Simulation, DAN and Code Injection.
Play with the Spell It GPT and try to break it. It is not impossible but (probably) fairly difficult to do 😉 Regardless, practice spelling and have fun!
Switch to Voice Mode in ChatGPT Mobile App to practice spelling and put headsets on for best results!